Overall Framework
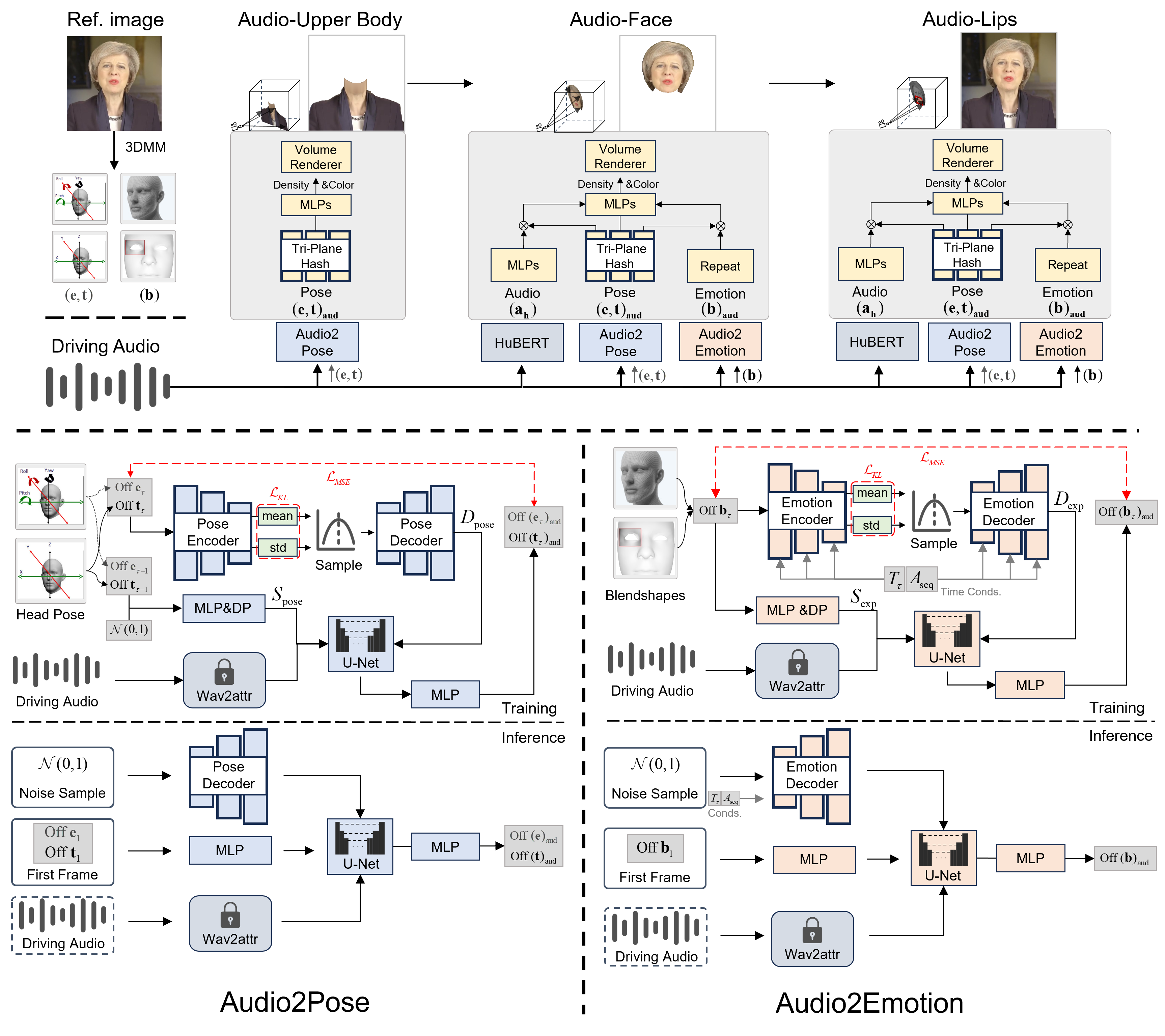
Existing 3D head avatar reconstruction methods rely on tracked FLAME meshes and a two-stage Gaussian rendering pipeline based on facial landmarks. However, misalignment between the estimated mesh and target images often leads to suboptimal rendering quality and loss of fine visual details. In this paper, we present MoGaFace, a novel 3D head avatar modeling framework that continuously refines facial geometry and texture attributes throughout the Gaussian rendering process. To address the misalignment between estimated FLAME meshes and target images, we introduce the Momentum-Guided Consistent Geometry module, which incorporates a momentum-updated expression bank and an expression-aware correction mechanism to ensure temporal and multi-view consistency. Additionally, we propose Latent Texture Attention, which encodes compact multi-view image features into head-aware representations, enabling geometry-aware texture refinement via integration into 3D Gaussians. Extensive experiments show that MoGaFace achieves high-fidelity head avatar reconstruction and significantly improves novel-view synthesis quality, even under inaccurate mesh initialization and unconstrained real-world settings.